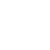这篇文章分享给大家的内容是关于最新AI修图软件DragGAN有多强大?,本文介绍得很详细,内容有一定的参考价值,能帮助大家进一步学习和理解“最新AI修图软件DragGAN有多强大?”,有这方面学习需要的朋友可以看看,接下来就让小编带领大家一起来学习一下吧。
这篇文章分享给大家的内容是关于最新AI修图软件DragGAN有多强大?,本文介绍得很详细,内容有一定的参考价值,能帮助大家进一步学习和理解“最新AI修图软件DragGAN有多强大?”,有这方面学习需要的朋友可以看看,接下来就让小编带领大家一起来学习一下吧。前言 如果甲方想把大象 P 转身,你只需要拖动 GAN 就好了。
本文转载自机器之心
仅用于学术分享,若侵权请联系删除
欢迎关注公众号CV技术指南,专注于计算机视觉的技术总结、最新技术跟踪、经典论文解读、CV招聘信息。
CV各大方向专栏与各个部署框架最全教程整理
【CV技术指南】CV全栈指导班、基础入门班、论文指导班 全面上线!!
在图像生成领域,以 Stable Diffusion 为代表的扩散模型已然成为当前占据主导地位的范式。但扩散模型依赖于迭代推理,这是一把双刃剑,因为迭代方法可以实现具有简单目标的稳定训练,但推理过程需要高昂的计算成本。
在 Stable Diffusion 之前,生成对抗网络(GAN)是图像生成模型中常用的基础架构。相比于扩散模型,GAN 通过单个前向传递生成图像,因此本质上是更高效的。但由于训练过程的不稳定性,扩展 GAN 需要仔细调整网络架构和训练因素。因此,GAN 方法很难扩展到非常复杂的数据集上,在实际应用方面,扩散模型比 GAN 方法更易于控制,这是 GAN 式微的原因之一。
当前,GAN 主要是通过手动注释训练数据或先验 3D 模型来保证其可控性,这通常缺乏灵活性、精确性和通用性。然而,一些研究者看重 GAN 在图像生成上的高效性,做出了许多改进 GAN 的尝试。
最近,来自马克斯・普朗克计算机科学研究所、MIT CSAIL 和谷歌的研究者们研究了一种控制 GAN 的新方法 DragGAN,能够让用户以交互的方式「拖动」图像的任何点精确到达目标点。

- 论文链接:https://arxiv.org/abs/2305.10973
- 项目主页:https://vcai.mpi-inf.mpg.de/projects/DragGAN/
这种全新的控制方法非常灵活、强大且简单,有手就行,只需在图像上「拖动」想改变的位置点(操纵点),就能合成你想要的图像。
例如,让狮子「转头」并「开口」:
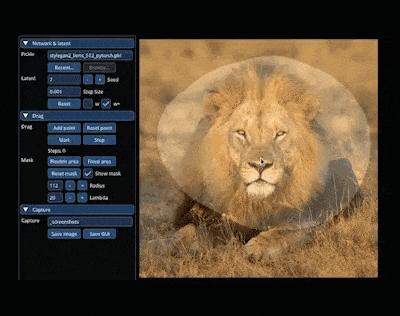
还能轻松让小猫 wink:
再比如,你可以通过拖动操纵点,让单手插兜的模特把手拿出来、改变站立姿势、短袖改长袖。看上去就像是同一个模特重新拍摄了新照片。
如果你也接到了「把大象转个身」的 P 图需求,不妨试试:
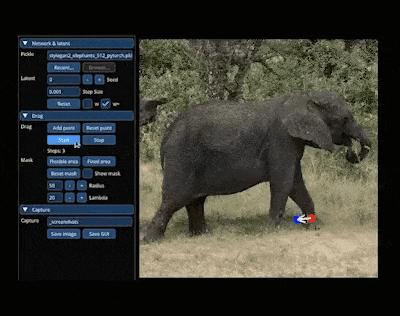


整个图像变换的过程就主打一个「简单灵活」,图像想怎么变就怎么变,因此有网友预言:「PS 似乎要过时了」。
也有人觉得,这个方法也可能会成为未来 PS 的一部分。

总之,观感就是一句话:「看到这个,我脑袋都炸了。」
当大家都以为 GAN 这个方向从此消沉的时候,总会出现让我们眼前一亮的作品:

这篇神奇的论文,已经入选了 SIGGRAPH 2023。研究者表示,代码将于六月开源。

那么,DragGAN 是如何做到强大又灵活的?我们来看一下该研究的技术方法。
方法概述
该研究提出的 DragGAN 主要由两个部分组成,包括:
- 基于特征的运动监督,驱动图像中的操纵点向目标位置移动;
- 一种借助判别型 GAN 特征的操纵点跟踪方法,以控制点的位置。
DragGAN 能够通过精确控制像素的位置对图像进行改变,可处理的图像类型包括动物、汽车、人类、风景等,涵盖大量物体姿态、形状、表情和布局,并且用户的操作方法简单通用。
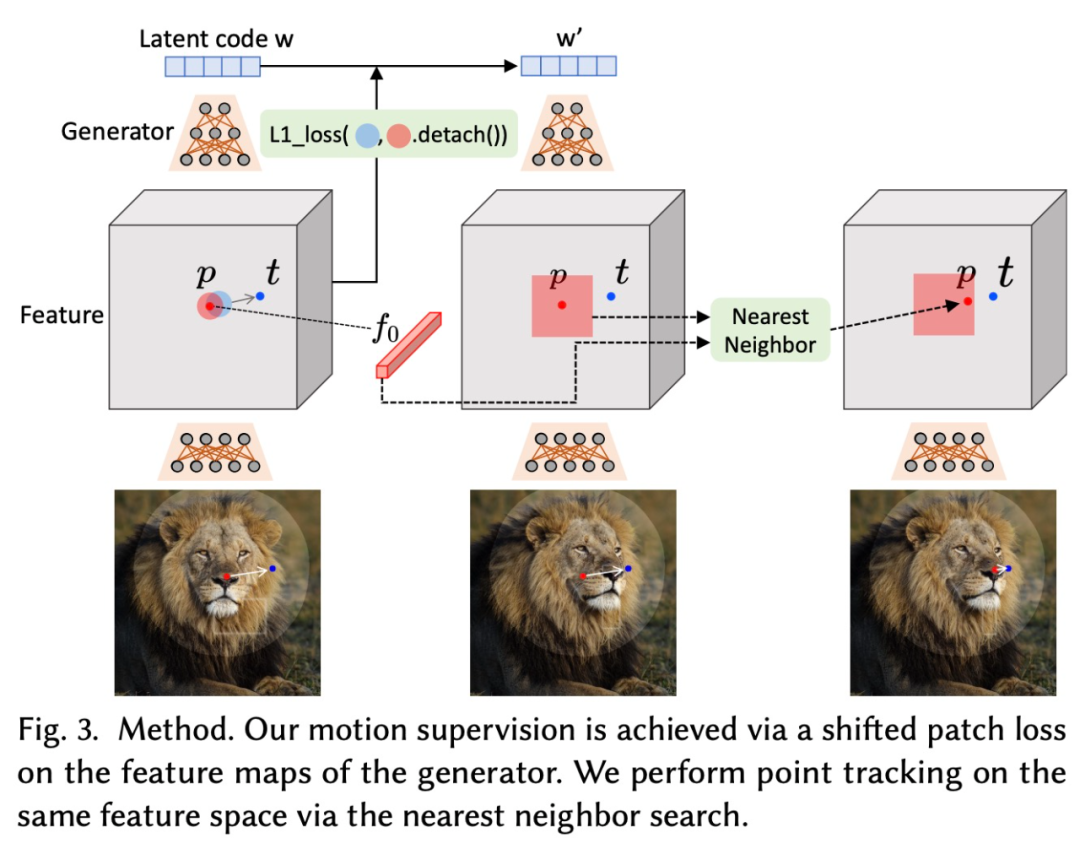
GAN 有一个很大的优势是特征空间具有足够的判别力,可以实现运动监督(motion supervision)和精确的点跟踪。具体来说,运动监督是通过优化潜在代码的移位特征 patch 损失来实现的。每个优化步骤都会导致操纵点更接近目标,然后通过特征空间中的最近邻搜索来执行点跟踪。重复此优化过程,直到操纵点达到目标。
DragGAN 还允许用户有选择地绘制感兴趣的区域以执行特定于区域的编辑。由于 DragGAN 不依赖任何额外的网络,因此它实现了高效的操作,大多数情况下在单个 RTX 3090 GPU 上只需要几秒钟就可以完成图像处理。这让 DragGAN 能够进行实时的交互式编辑,用户可以对图像进行多次变换更改,直到获得所需输出。
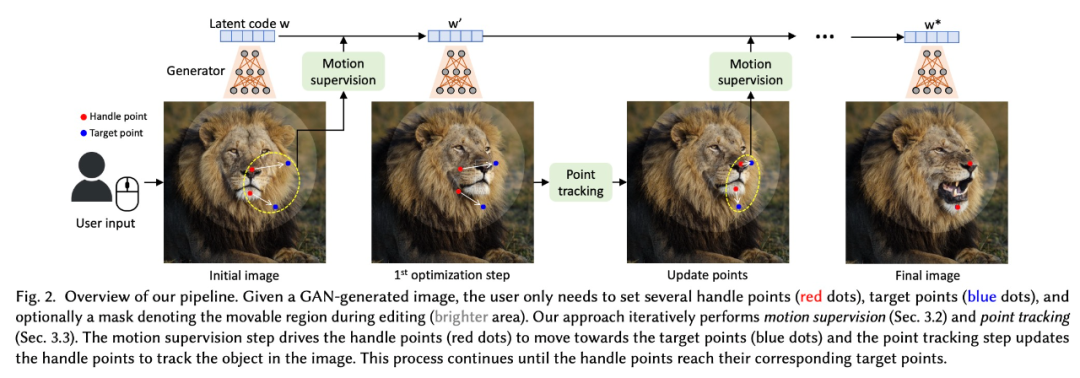
如下图所示,DragGAN 可以有效地将用户定义的操纵点移动到目标点,在许多目标类别中实现不同的操纵效果。与传统的形变方法不同的是,本文的变形是在 GAN 学习的图像流形上进行的,它倾向于遵从底层的目标结构,而不是简单地应用扭曲。例如,该方法可以生成原本看不见的内容,如狮子嘴里的牙齿,并且可以按照物体的刚性进行变形,如马腿的弯曲。

研究者还开发了一个 GUI,供用户通过简单地点击图像来交互地进行操作。
此外,通过与 GAN 反转技术相结合,本文方法还可以作为一个用于真实图像编辑的工具。
一个非常实用的用途是,即使合影中某些同学的表情管理不过关,你也可以为 Ta 换上自信的笑容:
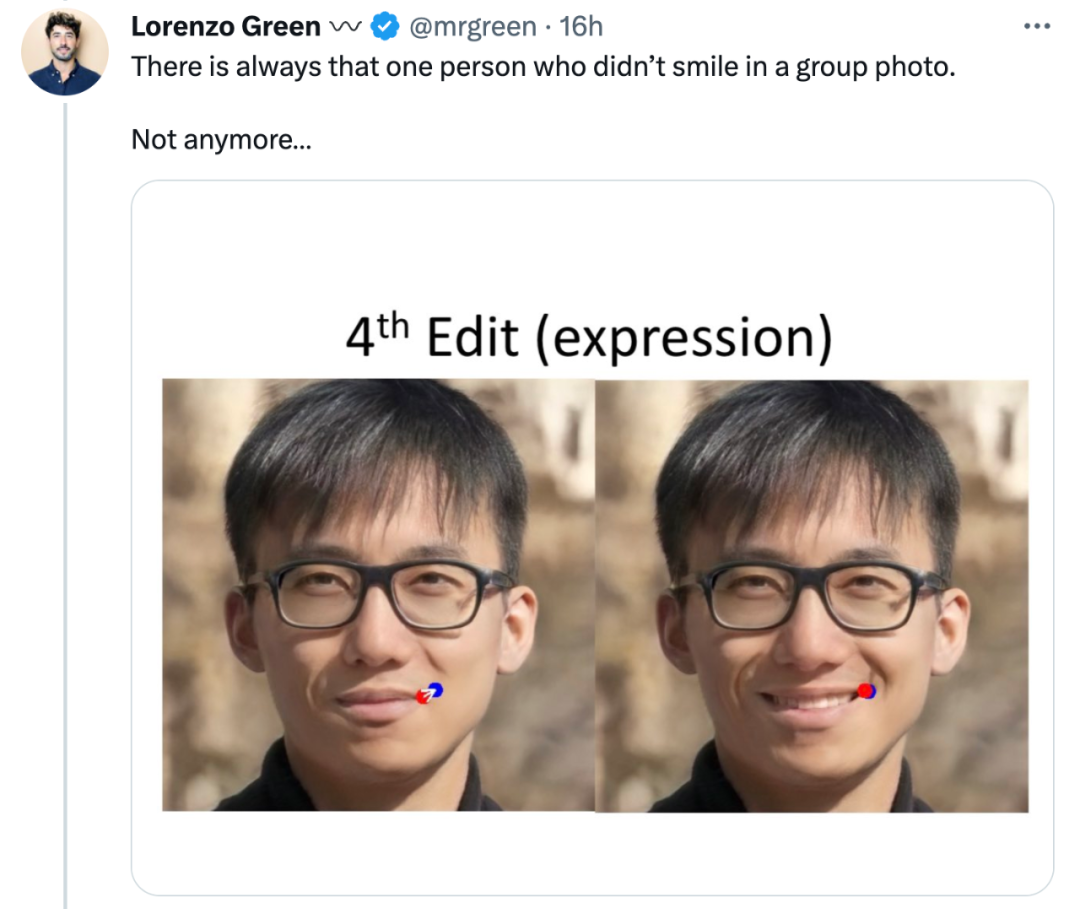
顺便提一句,这张照片正是本篇论文的一作潘新钢,2021 年在香港中文大学多媒体实验室获得博士学位,师从汤晓鸥教授。目前是马克斯普朗克信息学研究所博士后,并将从 2023 年 6 月开始担任南洋理工大学计算机科学与工程学院 MMLab 的任助理教授。
这项工作旨在为 GAN 开发一种交互式的图像操作方法,用户只需要点击图像来定义一些对(操纵点,目标点),并驱动操纵点到达其对应的目标点。
这项研究基于 StyleGAN2,基本架构如下:
在 StyleGAN2 架构中,一个 512 维的潜在代码 ∈N(0, )通过一个映射网络被映射到一个中间潜在代码 ∈R 512 中。 的空间通常被称为 W。然后, 被送到生成器 ,产生输出图像 I = ( )。在这个过程中, 被复制了几次,并被送到发生器 的不同层,以控制不同的属性水平。另外,也可以对不同层使用不同的 ,在这种情况下,输入将是
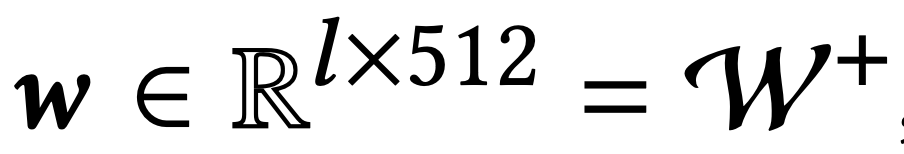
,其中 是层数。这种不太受约束的 W^+ 空间被证明是更有表现力的。由于生成器 学习了从低维潜在空间到高维图像空间的映射,它可以被看作是对图像流形的建模。
实验
为了展示 DragGAN 在图像处理方面的强大能力,该研究展开了定性实验、定量实验和消融实验。实验结果表明 DragGAN 在图像处理和点跟踪任务中均优于已有方法。
定性评估
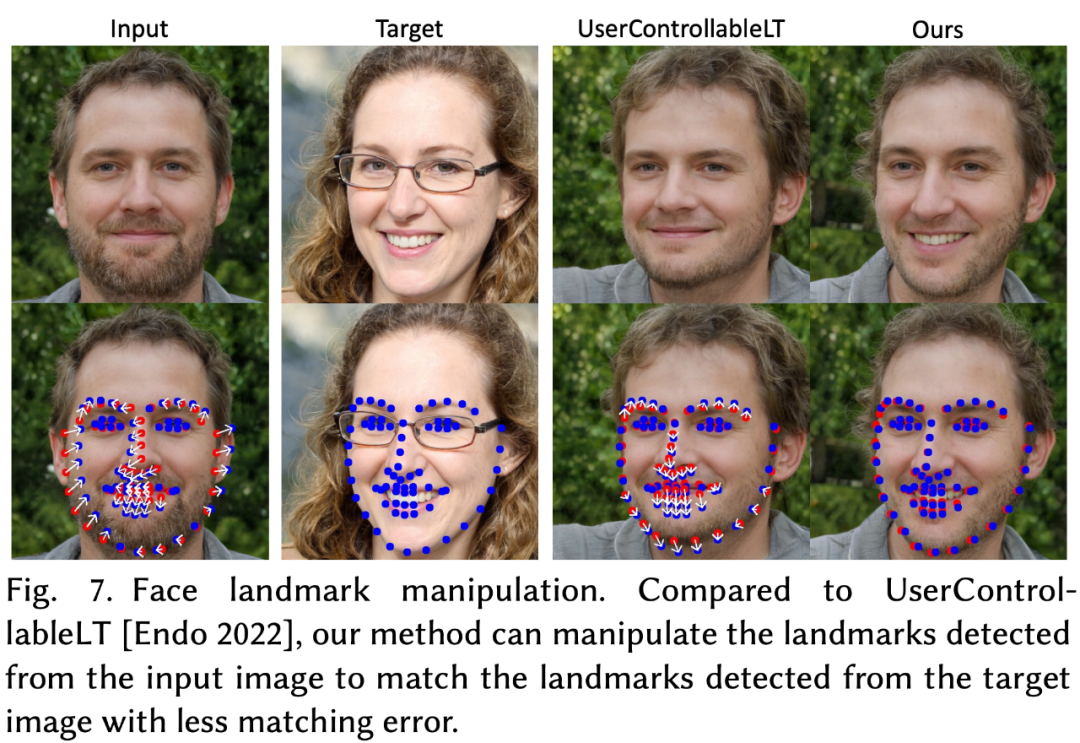
图 4 是本文方法和 UserControllableLT 之间的定性比较,展示了几个不同物体类别和用户输入的图像操纵结果。本文方法能够准确地移动操纵点以到达目标点,实现了多样化和自然的操纵效果,如改变动物的姿势、汽车形状和景观布局。相比之下,UserControllableLT 不能忠实地将操纵点移动到目标点上,往往会导致图像中出现不想要的变化。

如图 10 所示,它也不能像本文方法那样保持未遮盖区域固定不变。

图 6 提供了与 PIPs 和 RAFT 之间的比较,本文方法准确地跟踪了狮子鼻子上方的操纵点,从而成功地将它拖到了目标位置。

真实图像编辑。使用 GAN inversion 技术,将真实图像嵌入 StyleGAN 的潜空间,本文方法也可以用来操作真实图像。
图 5 显示了一个例子,将 PTI inversion 应用于真实图像,然后进行一系列的操作来编辑图像中人脸的姿势、头发、形状和表情:

图 13 展示了更多的真实图像编辑案例:

定量评估
研究者在两种设置中下对该方法进行了定量评估,包括人脸标记点操作和成对图像重建。
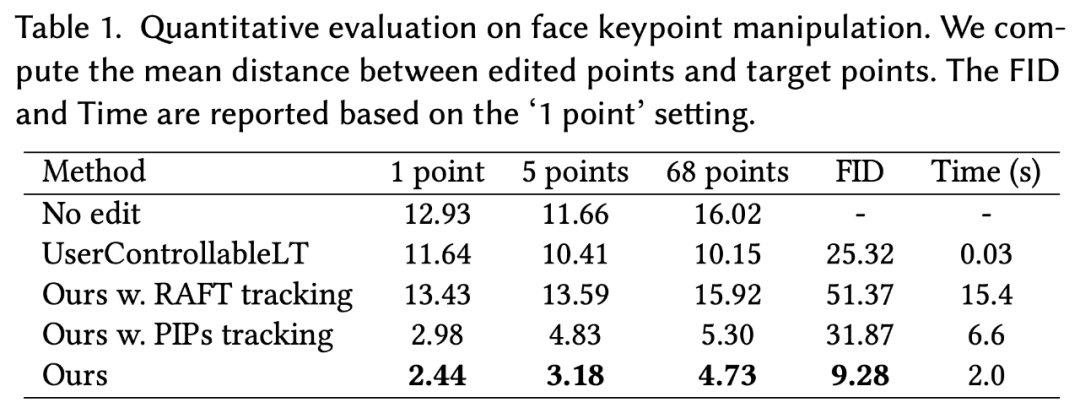
人脸标记点操作。如表 1 所示,在不同的点数下,本文方法明显优于 UserControllableLT。特别是,本文方法保留了更好的图像质量,正如表中的 FID 得分所示。
这种对比在图 7 中可以明显看出来,本文方法打开了嘴巴并调整下巴的形状以匹配目标脸,而 UserControllableLT 未能做到这一点。
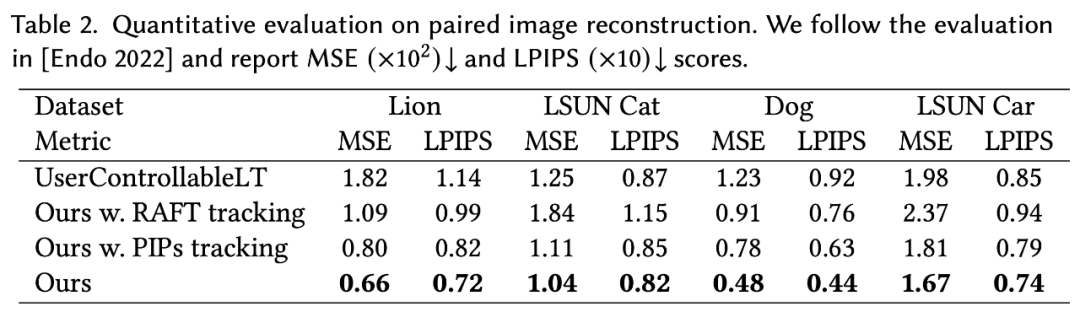
成对图像重建。如表 2 所示,本文方法在不同的目标类别中优于所有基线。
消融实验
研究者研究了在运动监督和点跟踪中使用某种特征的效果,并报告了使用不同特征的人脸标记点操作的性能(MD)。如表 3 所示,在运动监督和点跟踪中,StyleGAN 的第 6 个 block 之后的特征图表现最好,显示了分辨率和辨别力之间的最佳平衡。
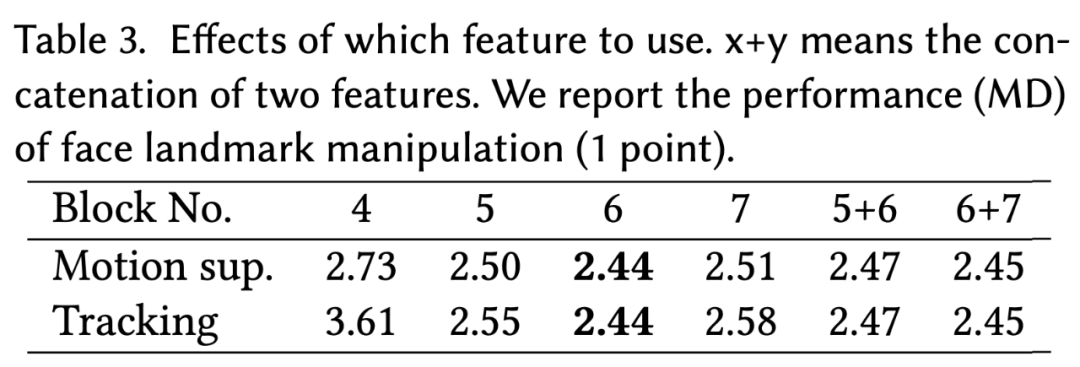
表 4 中提供了 _1 的效果。可以看出,性能对 _1 的选择不是很敏感,而 _1=3 的性能略好。

讨论
掩码的影响。本文方法允许用户输入一个表示可移动区域的二进制掩码,图 8 展示了它的效果:

Out-of-distribution 操作。从图 9 可以看出,本文的方法具有一定的 out-of-distribution 能力,可以创造出训练图像分布之外的图像,例如一个极度张开的嘴和一个大的车轮。

研究者同样指出了本文方法现存的局限性:尽管有一些推断能力,其编辑质量仍然受到训练数据多样性的影响。如图 14(a)所示,创建一个偏离训练分布的人体姿势会导致伪影。此外,如图 14(b)和(c)所示,无纹理区域的操纵点有时会在追踪中出现更多的漂移。因此,研究者建议尽可能挑选纹理丰富的操纵点。

欢迎关注公众号CV技术指南,专注于计算机视觉的技术总结、最新技术跟踪、经典论文解读、CV招聘信息。
计算机视觉入门1v3辅导班
【技术文档】《从零搭建pytorch模型教程》122页PDF下载
QQ交流群:470899183。群内有大佬负责解答大家的日常学习、科研、代码问题。
其它文章
CVPR'23|泛化到任意分割类别?FreeSeg:统一、通用的开放词汇图像分割新框架
全新YOLO模型YOLOCS来啦 | 面面俱到地改进YOLOv5的Backbone/Neck/Head
通用AI大型模型Segment Anything在医学图像分割领域的最新成果!
为何 CV 里没有出现类似 NLP 大模型的涌现现象?
可复现、自动化、低成本、高评估水平,首个自动化评估大模型的大模型PandaLM来了
实例:手写 CUDA 算子,让 Pytorch 提速 20 倍
NeRF与三维重建专栏(一)领域背景、难点与数据集介绍
异常检测专栏(三)传统的异常检测算法——上
异常检测专栏(二):评价指标及常用数据集
异常检测专栏(一)异常检测概述
BEV专栏(二)从BEVFormer看BEV流程(下篇)
BEV专栏(一)从BEVFormer深入探究BEV流程(上篇)
可见光遥感图像目标检测(三)文字场景检测之Arbitrary
可见光遥感目标检测(二)主要难点与研究方法概述
可见光遥感目标检测(一)任务概要介绍
TensorRT教程(三)TensorRT的安装教程
TensorRT教程(二)TensorRT进阶介绍
TensorRT教程(一)初次介绍TensorRT
AI最全资料汇总 | 基础入门、技术前沿、工业应用、部署框架、实战教程学习
计算机视觉入门1v3辅导班
计算机视觉交流群
聊聊计算机视觉入门
以上就是关于最新AI修图软件DragGAN有多强大?的介绍啦,需要的朋友可以参考上述内容,希望对大家有帮助,想要了解更多,欢迎关注群英网络,小编将为大家输出更多高质量的实用文章!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:mmqy2019@163.com进行举报,并提供相关证据,查实之后,将立刻删除涉嫌侵权内容。

2022-05-12 15:50:57
2023-06-06 09:55:26
2023-06-06 10:30:12
2023-06-06 09:28:54
2023-06-06 10:31:03
2023-06-06 10:29:56
2023-05-26 11:53:04
2023-06-06 09:22:10
2023-06-06 10:36:28
2023-06-06 10:35:26