相信很多人对“MySQL的聚集索引和非聚集索引有何差异”都不太了解,下面群英小编为你详细解释一下这个问题,希望对你有一定的帮助
相信很多人对“MySQL的聚集索引和非聚集索引有何差异”都不太了解,下面群英小编为你详细解释一下这个问题,希望对你有一定的帮助区别:1、聚集索引在叶子节点存储的是表中的数据,而非聚集索引在叶子节点存储的是主键和索引列;2、聚集索引中表记录的排列顺序和索引的排列顺序一致,而非聚集索引的排列顺序不一致;3、聚集索引每张表只能有一个,而非聚集索引可以有多个。

本教程操作环境:windows7系统、mysql8版本、Dell G3电脑。
MySQL的Innodb存储引擎的索引分为聚集索引和非聚集索引两大类,理解聚集索引和非聚集索引可通过对比汉语字典的索引。汉语字典提供了两类检索汉字的方式,第一类是拼音检索(前提是知道该汉字读音),比如拼音为cheng的汉字排在拼音chang的汉字后面,根据拼音找到对应汉字的页码(因为按拼音排序,二分查找很快就能定位),这就是我们通常所说的字典序;第二类是部首笔画检索,根据笔画找到对应汉字,查到汉字对应的页码。拼音检索就是聚集索引,因为存储的记录(数据库中是行数据、字典中是汉字的详情记录)是按照该索引排序的;笔画索引,虽然笔画相同的字在笔画索引中相邻,但是实际存储页码却不相邻,这是非聚集索引。
聚集索引
索引中键值的逻辑顺序决定了表中相应行的物理顺序。
聚集索引确定表中数据的物理顺序。聚集索引类似于电话簿,后者按姓氏排列数据。 聚集索引对于那些经常要搜索范围值的列特别有效。使用聚集索引找到包含第一个值的行后,便可以确保包含后续索引值的行在物理相邻。例如,如果应用程序执行 的一个查询经常检索某一日期范围内的记录,则使用聚集索引可以迅速找到包含开始日期的行,然后检索表中所有相邻的行,直到到达结束日期。这样有助于提高此 类查询的性能。同样,如果对从表中检索的数据进行排序时经常要用到某一列,则可以将该表在该列上聚集(物理排序),避免每次查询该列时都进行排序,从而节 省成本。
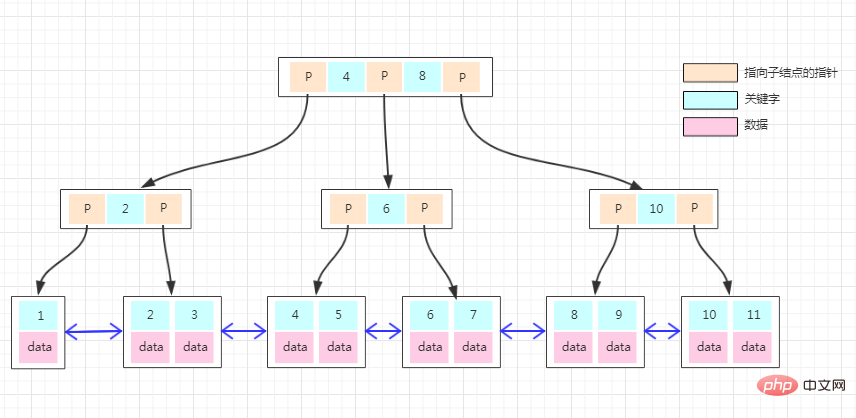
以上是innodb的b+tree索引结构
我们知道b+tree是从b-tree演变而来,一棵m阶的B-Tree有如下特性:
1、每个结点最多m个子结点。
2、除了根结点和叶子结点外,每个结点最少有m/2(向上取整)个子结点。
3、如果根结点不是叶子结点,那根结点至少包含两个子结点。
4、所有的叶子结点都位于同一层。
5、每个结点都包含k个元素(关键字),这里m/2≤k<m,这里m/2向下取整。
6、每个节点中的元素(关键字)从小到大排列。
7、每个元素(关键字)字左结点的值,都小于或等于该元素(关键字)。右结点的值都大于或等于该元素(关键字)。
b+tree的特点是:
1、所有的非叶子节点只存储关键字信息。
2、所有卫星数据(具体数据)都存在叶子结点中。
3、所有的叶子结点中包含了全部元素的信息。
4、所有叶子节点之间都有一个链指针。
我们发现,b+trre有以下特性:
- 对一个范围内的查询特别有效快速(通过叶子的链指针);
- 对具体的key值查询仅仅比b-tree低效一点(因为要到叶子一级),但也可以忽略;
非聚集索引
索引中索引的逻辑顺序与磁盘上行的物理存储顺序不同。
其实按照定义,除了聚集索引以外的索引都是非聚集索引,只是人们想细分一下非聚集索引,分成普通索引,唯一索引,全文索引。如果非要把非聚集索引类比成现实生活中的东西,那么非聚集索引就像新华字典的偏旁字典,他结构顺序与实际存放顺序不一定一致。
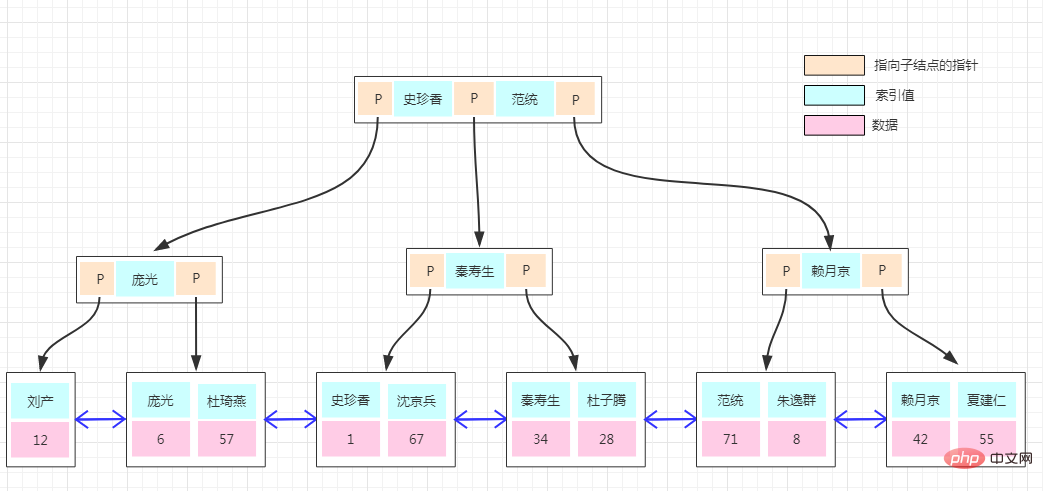
非聚集索引的存储结构与前面是一样的,不同的是在叶子结点的数据部分存的不再是具体的数据,而数据的聚集索引的key。所以通过非聚集索引查找的过程是先找到该索引key对应的聚集索引的key,然后再拿聚集索引的key到主键索引树上查找对应的数据,这个过程称为回表!
举个例子说明下:
create table student ( `id` INT UNSIGNED AUTO_INCREMENT, `username` VARCHAR(255), `score` INT, PRIMARY KEY(`id`), KEY(`username`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8;
聚集索引clustered index(id), 非聚集索引index(username)。
使用以下语句进行查询,不需要进行二次查询,直接就可以从非聚集索引的节点里面就可以获取到查询列的数据。
select id, username from t1 where username = '小明' select username from t1 where username = '小明'
但是使用以下语句进行查询,就需要二次的查询去获取原数据行的score:
select username, score from t1 where username = '小明'
聚集索引和非聚集索引区别
区别一:
聚集索引:就是以主键创建的索引,在叶子节点存储的是表中的数据
非聚集索引:就是以非主键创建的索引(也叫做二级索引),在叶子节点存储的是主键和索引列。
区别二:
聚集索引中表记录的排列顺序和索引的排列顺序一致;所以查询效率快,因为只要找到第一个索引值记录,其余的连续性的记录在物理表中也会连续存放,一起就可以查询到。缺点:新增比较慢,因为为了保证表中记录的物理顺序和索引顺序一致,在记录插入的时候,会对数据页重新排序。
非聚集索引中表记录的排列顺序和索引的排列顺序不一致。
区别三:
聚集索引是物理上连续存在,而非聚集索引是逻辑上的连续,物理存储不连续。
区别四:
聚集索引每张表只能有一个,非聚集索引可以有多个。
通过以上内容的阐述,相信大家对“MySQL的聚集索引和非聚集索引有何差异”已经有了进一步的了解,更多相关的问题,欢迎关注群英网络或到群英官网咨询客服。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:mmqy2019@163.com进行举报,并提供相关证据,查实之后,将立刻删除涉嫌侵权内容。

2022-02-09 17:56:31
2022-06-14 17:41:20
2021-11-08 17:46:28
2022-05-11 11:57:27
2021-11-08 15:41:44
2022-05-07 17:44:08
2021-11-22 17:53:28
2021-11-08 17:46:26
2022-05-14 14:55:09
2022-05-10 17:41:30