Python里怎么样做数据透视表?
Admin发表于 2021-12-29 18:30:501350 次浏览

Python里怎么样做数据透视表?在我们工作中经常会遇到需要做数据透视表,它能很快的帮我们收集我们想要的数据,而在用Python里的Pandas可以实现,虽然不如Excel方便,但是效果也还不错,接下来我们一起了解看看吧。
1.groupby + agg
不够直观,不好看
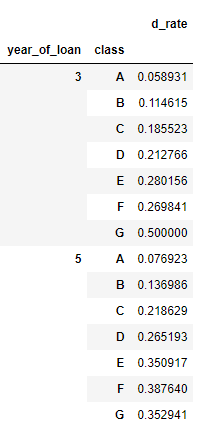
对贷款年份,贷款种类创建数据透视
train_data.groupby(['year_of_loan', 'class']).agg(d_roat =('isDefault', 'mean'))
2. crosstab
pandas.crosstab(index, columns,values, rownames=None, colnames, aggfunc, margins, margins_name, dropna, normalize)
主要用到的参数:
index:选哪个变量做数据透视表的行
columns:选哪个变量做数据透视表的列
values:要聚合的值
aggfunc:使用的聚合函数
margins:是否添加汇总列/行
margins_name:汇总行/列的名字
例子
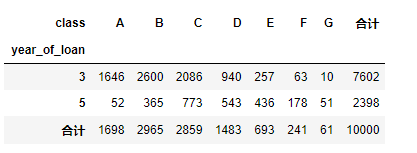
对贷款年份,贷款种类创建数据透视
pd.crosstab(train_data['year_of_loan'], train_data['class'], train_data['loan_id'],
aggfunc='count',margins = True, margins_name = '合计')
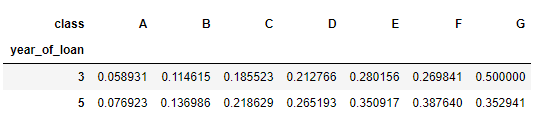
可以直接看出交叉组合之后违约比例
pd.crosstab(train_data['year_of_loan'], train_data['class'], train_data['isDefault'], aggfunc='mean')
3.groupby + pivot
train_data.groupby(['year_of_loan', 'class'],
as_index = False)['isDefault'].mean().pivot('year_of_loan', 'class', 'isDefault')
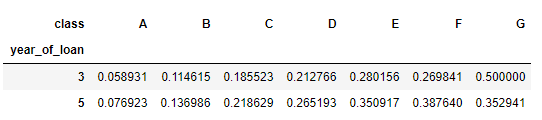
pivot_table
pandas.pivot_table(data, values, index, columns, aggfunc, fill_value, margins, dropna, margins_name, observed, sort)
常用参数与crosstab一致
例子
实现同样的数据透视表
pandas.pivot_table(data, values, index, columns, aggfunc, fill_value, margins, dropna, margins_name, observed, sort)

pd.pivot_table(train_data[['year_of_loan', 'class', 'isDefault']], values='isDefault', index=['year_of_loan'], columns=['class'], aggfunc='mean')
总结
以上就是Python里实现数据透视表的几种方法,有些展现效果不是很好,有些数据显示的很清晰,有需要的朋友可以参考了解看看,本文代码有一定的参考价值。最好,想要了解更多可以继续浏览群英网络其他相关的文章。
文本转载自脚本之家
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:mmqy2019@163.com进行举报,并提供相关证据,查实之后,将立刻删除涉嫌侵权内容。
标签:
python数据透视表
相关信息推荐
2022-07-19 17:37:08
2022-12-01 16:14:54
2022-08-24 16:47:11

2022-12-14 11:21:38
2022-08-19 17:53:01
2022-08-19 17:51:59
python数据透视表
post
php超全局变量
mysql组合索引
Vue组件
golang套接字是否关闭
内联函数
InnoDB组件结构
php照片上传
spring-retry是什么
百度CDN公共库
location顺序
PHP观察者模式
mysql事务隔离级别
提示词
php分割数组
remote的用法
oracle查看死锁
python中itertools模块
python打印水仙花数
list
python版本查看
Ajax异步加载数据
字符串
HTML5中使用SVG
Java后端开发
生命周期
分布式数据库事务
数据转换
查询事务隔离级别
2022-01-24 19:23:44
2022-02-25 17:19:26
2022-01-04 18:53:44
2022-01-26 18:39:38
2021-11-20 17:46:01
2022-01-18 18:00:09
2022-01-13 18:58:11
2022-01-24 19:23:57
2021-11-22 17:53:55
2021-11-20 17:45:40

群英网络助力开启安全的云计算之旅



Copyright © QY Network Company Ltd. All Rights Reserved. 2003-2019 群英网络 版权所有 茂名市群英网络有限公司
增值电信经营许可证 : B1.B2-20140078 粤ICP备09006778号