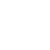如何利用实现筛选简历,方法是什么
Admin发表于 2022-07-23 17:42:42646 次浏览
 这篇文章主要给大家介绍“如何利用实现筛选简历,方法是什么”的相关知识,下文通过实际案例向大家展示操作过程,内容简单清晰,易于学习,有这方面学习需要的朋友可以参考,希望这篇“如何利用实现筛选简历,方法是什么”文章能对大家有所帮助。
这篇文章主要给大家介绍“如何利用实现筛选简历,方法是什么”的相关知识,下文通过实际案例向大家展示操作过程,内容简单清晰,易于学习,有这方面学习需要的朋友可以参考,希望这篇“如何利用实现筛选简历,方法是什么”文章能对大家有所帮助。
简历筛选
简历相关信息如下:

定义 ReadDoc 类用以读取 word 文件
已知条件:
想要查找包含指定关键字的简历(比如 Python、Java)
实现思路:
批量读取每一个 word 文件(通过 glob 获取 word 信息),将他们的所有可读内容获取,并通过关键字方式筛选,拿到目标简历地址。
这里有个需要注意的地方就是,并不是所有的 "简历" 都是以段落的形式呈现的,比如从 "猎聘" 网下载下来的简历就是 "表格形式" 的,而 "boss" 上下载的简历就是 "段落形式" 的,这里再进行读取的时候需要注意下,我们做的演示脚本练习就是 "表格形式" 的。
这里的话,我们就可以专门定义一个 "ReadDoc" 的类,里面定义两个函数,分别用于读取 "段落" 和 "表格" 。
实操案例脚本如下:
# coding:utf-8from docx import Documentclass ReadDoc(object): # 定义一个 ReadDoc ,用以读取 word 文件
def __init__(self, path): # 构造函数默认传入读取 word 文件的路径
self.doc = Document(path)
self.p_text = ''
self.table_text = ''
self.get_para()
self.get_table()
def get_para(self): # 定义 get_para 函数用以读取 word 文件的段落
for p in self.doc.paragraphs:
self.p_text += p.text + '\n' # 读取的段落内容进行换行
print(self.p_text)
def get_table(self): # 定义 get_table 函数循环读取表格内容
for table in self.doc.tables:
for row in table.rows:
_cell_str = '' # 获取每一行的完整信息
for cell in row.cells:
_cell_str += cell.text + ',' # 每一行加一个 "," 隔开
self.table_text += _cell_str + '\n' # 读取的表格内容进行换行
print(self.table_text)if __name__ == '__main__':
path = glob.os.path.join(glob.os.getcwd(), 'test_file/简历1.docx')
doc = ReadDoc(path)
print(doc)看一下 ReadDoc 类的运行结果
定义 search_word 函数用以筛选 word 文件内容符合想要的简历
OK,上文已经成功读取了简历的 word 文档,接下来我们要将读取到的内容通过帅选关键字信息的方式,过滤出包含有关键字的简历。
实操案例脚本如下:
# coding:utf-8import globfrom docx import Documentclass ReadDoc(object): # 定义一个 ReadDoc ,用以读取 word 文件
def __init__(self, path): # 构造函数默认传入读取 word 文件的路径
self.doc = Document(path)
self.p_text = ''
self.table_text = ''
self.get_para()
self.get_table()
def get_para(self): # 定义 get_para 函数用以读取 word 文件的段落
for p in self.doc.paragraphs:
self.p_text += p.text + '\n' # 读取的段落内容进行换行
# print(self.p_text) # 调试打印输出 word 文件的段落内容
def get_table(self): # 定义 get_table 函数循环读取表格内容
for table in self.doc.tables:
for row in table.rows:
_cell_str = '' # 获取每一行的完整信息
for cell in row.cells:
_cell_str += cell.text + ',' # 每一行加一个 "," 隔开
self.table_text += _cell_str + '\n' # 读取的表格内容进行换行
# print(self.table_text) # 调试打印输出 word 文件的表格内容def search_word(path, targets): # 定义 search_word 用以筛选符合内容的简历;传入 path 与 targets(targets 为列表)
result = glob.glob(path)
final_result = [] # 定义一个空列表,用以后续存储文件的信息
for i in result: # for 循环获取 result 内容
isuse = True # 是否可用
if glob.os.path.isfile(i): # 判断是否是文件
if i.endswith('.docx'): # 判断文件后缀是否是 "docx" ,若是,则利用 ReadDoc类 实例化该文件对象
doc = ReadDoc(i)
p_text = doc.p_text # 获取 word 文件内容
table_text = doc.table_text
all_text = p_text + table_text for target in targets: # for 循环判断关键字信息内容是否存在
if target not in all_text:
isuse = False
break
if not isuse:
continue
final_result.append(i)
return final_resultif __name__ == '__main__':
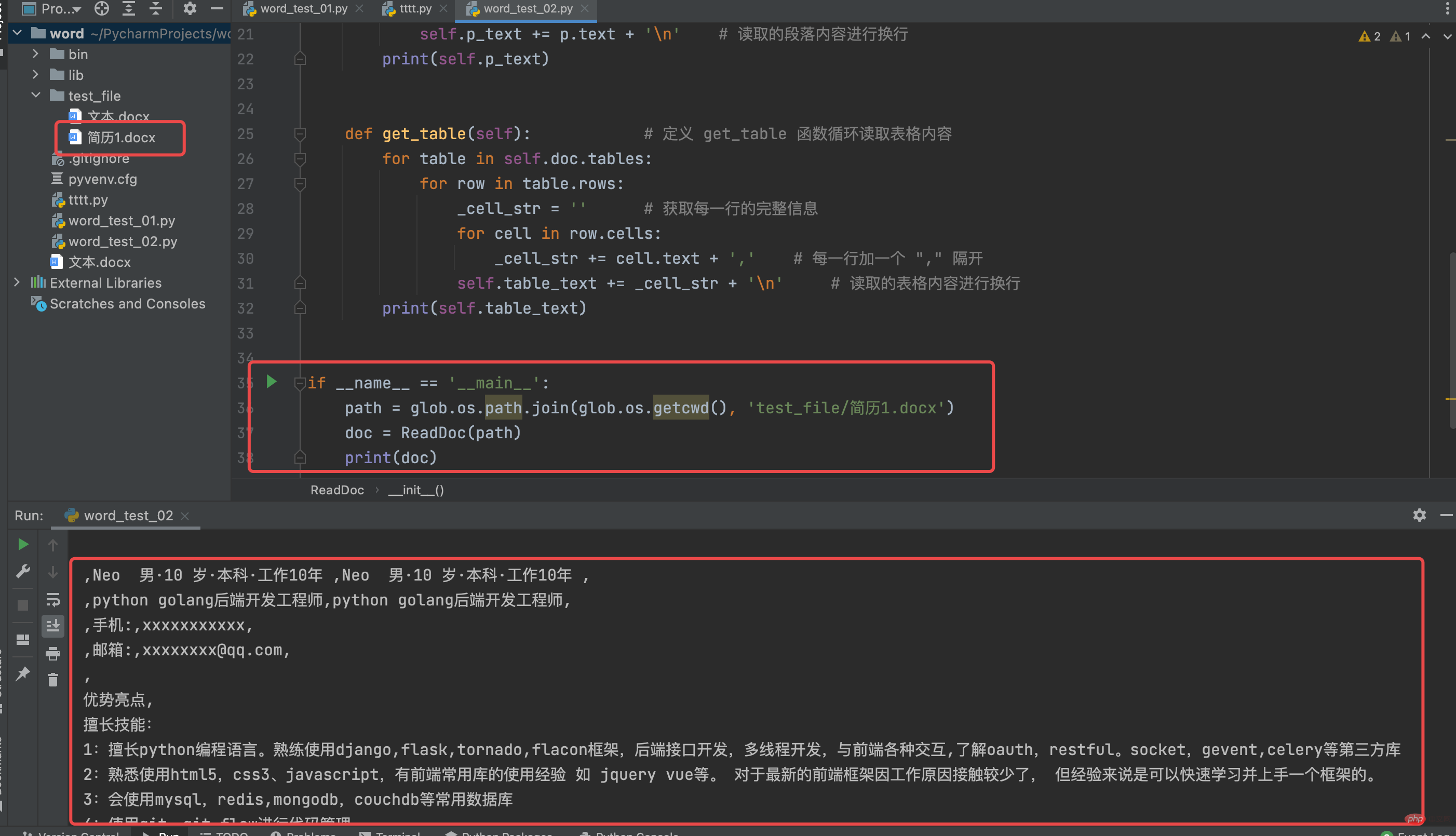
path = glob.os.path.join(glob.os.getcwd(), '*')
result = search_word(path, ['python', 'golang', 'react', '埋点']) # 埋点是为了演示效果,故意在 "简历1.docx" 加上的
print(result)运行结果如下:
以上就是关于如何利用实现筛选简历,方法是什么的介绍啦,需要的朋友可以参考上述内容,希望对大家有帮助,欢迎关注群英网络,小编将为大家输出更多高质量的实用文章!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:mmqy2019@163.com进行举报,并提供相关证据,查实之后,将立刻删除涉嫌侵权内容。
标签:
python
相关信息推荐
2022-05-09 17:23:32
2022-10-28 17:50:58
2021-12-30 20:35:26

2022-12-14 11:21:38
2022-08-19 17:53:01
2022-08-19 17:51:59
Python3
chatgpt,交互式地图,python,folium
ChatGPT中文,Python代码,对话ChatGPT,方便
python安装目录
JSON在Python中的使用
python日志发送到远端
Python猜谜游戏
Python垃圾回收
Python傅里叶变化
python模板文件创建使用
python游戏小地图
Python跳板机访问
Python绘制思维导图
Python命令
Python获取响应
python操作svn
python高级特性
Python字符串格式化
python语言元素
python连接telnet和ssh
python地图画线
IDA找不到Python模块
python分布式锁
python图片处理库Pillow
Python处理字符串函数
python精准搜索
python遍历求和
python线上问题排查
python Bokeh库
Python实用技巧
2022-01-24 19:23:44
2022-02-25 17:19:26
2022-01-04 18:53:44
2022-01-26 18:39:38
2021-11-20 17:46:01
2022-01-18 18:00:09
2022-01-13 18:58:11
2022-01-24 19:23:57
2021-11-22 17:53:55
2021-11-20 17:45:40

群英网络助力开启安全的云计算之旅



Copyright © QY Network Company Ltd. All Rights Reserved. 2003-2019 群英网络 版权所有 茂名市群英网络有限公司
增值电信经营许可证 : B1.B2-20140078 粤ICP备09006778号