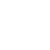python爬虫爬取网页图片的方法步骤是什么?
Admin发表于 2022-07-22 17:44:20803 次浏览
上一篇: Python高效数据处理的技巧方法有什么
 这篇文章给大家分享的是“python爬虫爬取网页图片的方法步骤是什么?”,文中的讲解内容简单清晰,对大家认识和了解都有一定的帮助,对此感兴趣的朋友,接下来就跟随小编一起了解一下“python爬虫爬取网页图片的方法步骤是什么?”吧。
这篇文章给大家分享的是“python爬虫爬取网页图片的方法步骤是什么?”,文中的讲解内容简单清晰,对大家认识和了解都有一定的帮助,对此感兴趣的朋友,接下来就跟随小编一起了解一下“python爬虫爬取网页图片的方法步骤是什么?”吧。
在现在这个信息爆炸的时代,要想高效的获取数据,爬虫是非常好用的。而用python做爬虫也十分简单方便,下面通过一个简单的小爬虫程序来看一看写爬虫的基本过程:
准备工作
语言:python
IDE:pycharm
首先是要用到的库,因为是刚入门最简单的程序,我们主要就用到下面这两:
import requests //用于请求网页 import re //正则表达式,用于解析筛选网页中的信息
其中re是python自带的,requests库需要我们自己安装,在命令行中输入pip install requests即可。
然后随便找一个网站,注意不要尝试爬取隐私敏感信息,这里找了个表情包网站:
注:此处表情包网站中的内容本来就可以免费下载,所以爬虫只是简化了我们一个个点的流程,注意不能去爬取付费资源。
我们要做的就是通过爬虫把这些表情包下载到我们电脑里。
编写爬虫程序
首先肯定要通过python访问这个网站,代码如下:
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:98.0) Gecko/20100101 Firefox/98.0'
}
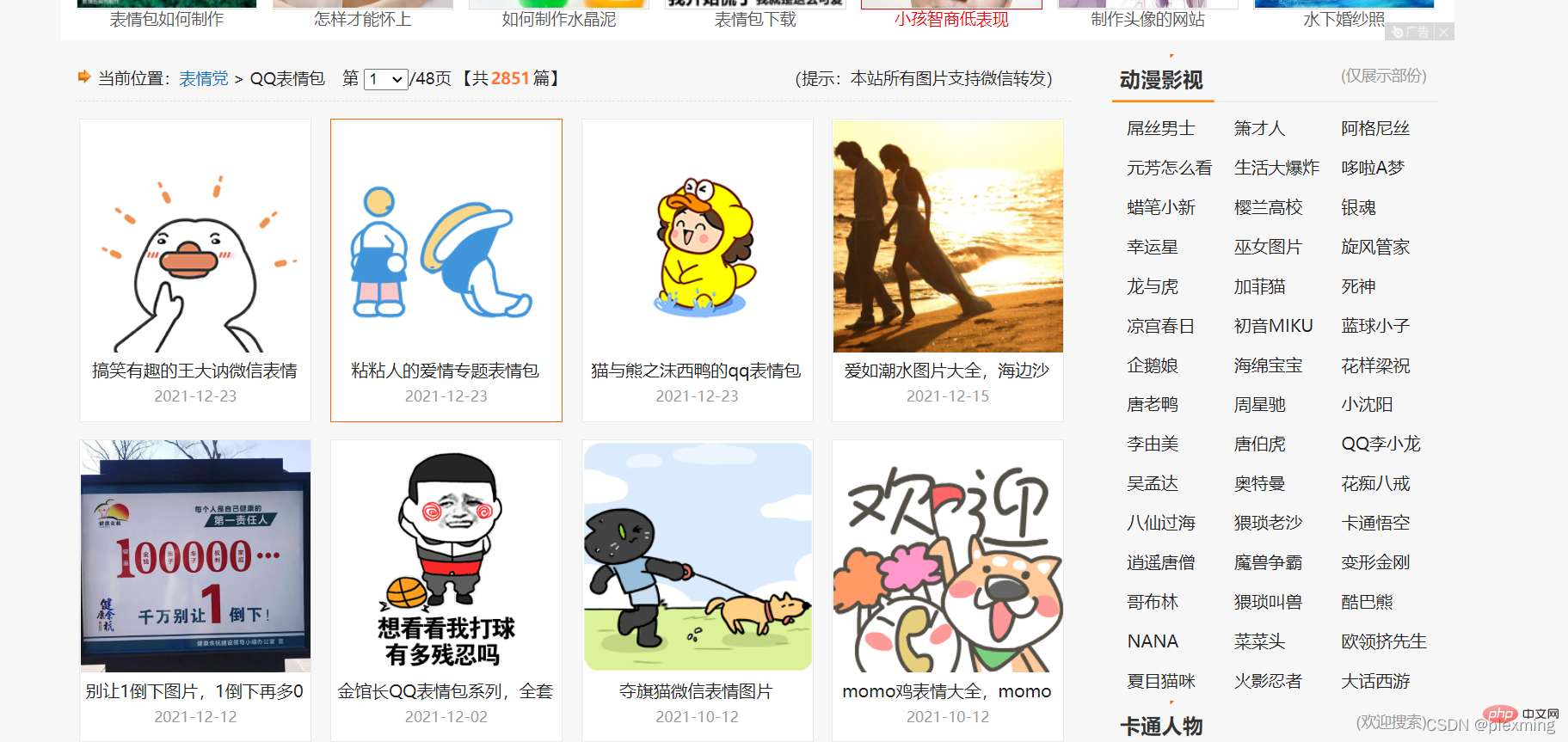
response = requests.get('https://qq.yh31.com/zjbq/',headers=headers) //请求网页其中之所以要加headers这一段是因为有些网页会识别到你是通过python请求的然后把你拒绝,所以我们要换个正常的请求头。可以随便找一个或者f12从网络信息里复制一个。
然后我们要找到我们要爬取的图片在网页代码里的位置,f12查看源代码,找到表情包如下:

然后建立匹配规则,用正则表达式把中间那串替换掉,最简单的就是.*?
t = '<img src="(.*?)" alt="(.*?)" width="160" height="120">'
像这样。
然后就可以调用re库里的findall方法把相关内容爬下来了:
result = re.findall(t, response.text)
返回的内容是由字符串组成的列表,最后我们经由爬到的地址通过python语句把图片下下来保存到文件夹里就行了。
程序代码
import requests
import re
import os
image = '表情包'
if not os.path.exists(image):
os.mkdir(image)
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:98.0) Gecko/20100101 Firefox/98.0'
}
response = requests.get('https://qq.yh31.com/zjbq/',headers=headers)
response.encoding = 'GBK'
response.encoding = 'utf-8'
print(response.request.headers)
print(response.status_code)
t = '<img src="(.*?)" alt="(.*?)" width="160" height="120">'
result = re.findall(t, response.text)
for img in result:
print(img)
res = requests.get(img[0])
print(res.status_code)
s = img[0].split('.')[-1] #截取图片后缀,得到表情包格式,如jpg ,gif
with open(image + '/' + img[1] + '.' + s, mode='wb') as file:
file.write(res.content)最后结果就是这个样子:

感谢各位的阅读,以上就是“python爬虫爬取网页图片的方法步骤是什么?”的内容了,通过以上内容的阐述,相信大家对python爬虫爬取网页图片的方法步骤是什么?已经有了进一步的了解,如果想要了解更多相关的内容,欢迎关注群英网络,群英网络将为大家推送更多相关知识点的文章。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:mmqy2019@163.com进行举报,并提供相关证据,查实之后,将立刻删除涉嫌侵权内容。
标签:
python
上一篇: Python高效数据处理的技巧方法有什么
相关信息推荐
2022-08-13 17:50:43
2022-06-16 09:25:44
2021-12-01 19:07:06

2022-12-14 11:21:38
2022-08-19 17:53:01
2022-08-19 17:51:59
Python3
chatgpt,交互式地图,python,folium
ChatGPT中文,Python代码,对话ChatGPT,方便
python安装目录
JSON在Python中的使用
python日志发送到远端
Python猜谜游戏
Python垃圾回收
Python傅里叶变化
python模板文件创建使用
python游戏小地图
Python跳板机访问
Python绘制思维导图
Python命令
Python获取响应
python操作svn
python高级特性
Python字符串格式化
python语言元素
python连接telnet和ssh
python地图画线
IDA找不到Python模块
python分布式锁
python图片处理库Pillow
Python处理字符串函数
python精准搜索
python遍历求和
python线上问题排查
python Bokeh库
Python实用技巧
2022-02-25 17:19:26
2022-01-24 19:23:44
2022-01-04 18:53:44
2022-01-26 18:39:38
2021-11-20 17:46:01
2022-01-18 18:00:09
2022-01-13 18:58:11
2022-01-24 19:23:57
2021-11-22 17:53:55
2021-11-20 17:45:40

群英网络助力开启安全的云计算之旅



Copyright © QY Network Company Ltd. All Rights Reserved. 2003-2019 群英网络 版权所有 茂名市群英网络有限公司
增值电信经营许可证 : B1.B2-20140078 粤ICP备09006778号