在Python中html文件乱码情况如何处理
Admin发表于 2022-07-19 17:34:101343 次浏览
上一篇: Golang交叉编译是怎样的,要点是什么
 今天这篇给大家分享的知识是“在Python中html文件乱码情况如何处理”,小编觉得挺不错的,对大家学习或是工作可能会有所帮助,对此分享发大家做个参考,希望这篇“在Python中html文件乱码情况如何处理”文章能帮助大家解决问题。
今天这篇给大家分享的知识是“在Python中html文件乱码情况如何处理”,小编觉得挺不错的,对大家学习或是工作可能会有所帮助,对此分享发大家做个参考,希望这篇“在Python中html文件乱码情况如何处理”文章能帮助大家解决问题。
python写入html文件中文乱码问题
使用open函数将爬虫爬取的html写入文件,有时候在控制台不会乱码,但是写入文件的html中的中文是乱码的
案例分析
看下面一段代码:
# 爬虫未使用cookiefrom urllib import requestif __name__ == '__main__':
url = "http://www.renren.com/967487029/profile"
rsp = request.urlopen(url)
html = rsp.read().decode() with open("rsp.html","w")as f: # 将爬取的页面
print(html)
f.write(html)看似没有问题,并且在控制台输出的html也不会出现中文乱码,但是创建的html文件中
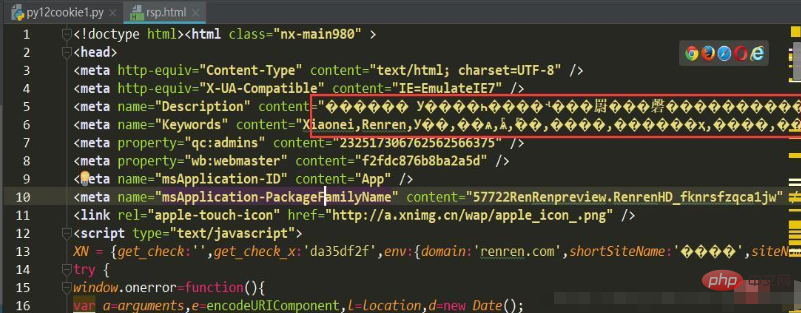
解决方案
使用open方法的一个参数,名为encoding=” “,加入encoding=”utf-8”即可
# 爬虫未使用cookiefrom urllib import requestif __name__ == '__main__':
url = "http://www.renren.com/967487029/profile"
rsp = request.urlopen(url)
html = rsp.read().decode() with open("rsp.html","w",encoding="utf-8")as f: # 将爬取的页面
print(html)
f.write(html)运行结果
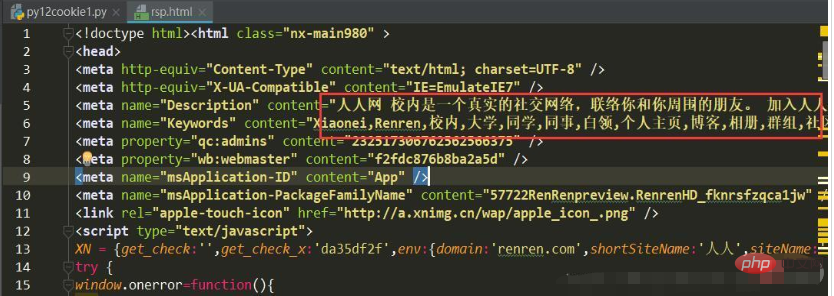
现在大家对于在Python中html文件乱码情况如何处理的内容应该都清楚了吧,希望大家阅读完这篇文章能有所收获。最后,想要了解更多在Python中html文件乱码情况如何处理的知识,欢迎关注群英网络,群英网络将为大家推送更多相关知识点的文章。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:mmqy2019@163.com进行举报,并提供相关证据,查实之后,将立刻删除涉嫌侵权内容。
标签:
html文件乱码
上一篇: Golang交叉编译是怎样的,要点是什么
相关信息推荐
2022-08-10 17:55:25
2022-06-24 17:32:03
2022-05-31 17:40:52

2022-12-14 11:21:38
2022-08-19 17:53:01
2022-08-19 17:51:59
html文件乱码
表和数据库的关系
故障定位
php-fpm启动脚本
查询数组元素
oracle update
ID自动增长
mysql远程连接不上
python怎么画圆
整数类型int
room数据库
golang设置定时任务
js,防抖,节流
php 获取文件类型
返回值中文乱码
gopath
java的三大体系
云计算之路:数据库服务器的选择——舍RDS取云服务器
云服务器
decode函数用法de
微信小程序弹出菜单
CDN域名集合
python mysql的连接池
CDN归纳理解
php5和php7
Spring 泛型注入
c语言数组初始化
mysql数据清理
jvm加载类的过程
CentOS系统,CentOS下,Mariadb数据库的性能优化,安全性配置
bootstrap-datepicker
2022-02-25 17:19:26
2022-01-24 19:23:44
2022-01-04 18:53:44
2022-01-26 18:39:38
2021-11-20 17:46:01
2022-01-18 18:00:09
2022-01-13 18:58:11
2022-01-24 19:23:57
2021-11-22 17:53:55
2021-11-20 17:45:40

群英网络助力开启安全的云计算之旅



Copyright © QY Network Company Ltd. All Rights Reserved. 2003-2019 群英网络 版权所有 茂名市群英网络有限公司
增值电信经营许可证 : B1.B2-20140078 粤ICP备09006778号